Questo vocabolario, edito a Ravenna dalla fondazione della banca del monte, nel 1977, è una opera per noi molto importante, e abbiamo deciso di analizzarla, per estrarne le voci.

Abbiamo reperito una scansione digitale di buona qualità di questa opera, presso il sito archive.org

Per l’analisi di questo materiale, che include un output OCR di qualità inadeguata, abbiamo sviluppato una serie di procedure software dedicate, per la segmentazione delle pagine, portandole in colonna singola, per la bonifica da bitmap indesiderati, la correzione di difetti di skewing (rotazioni).
Queste attività sono state svolte con l’utilizzo di apposito software da noi scritto per il bitmap processing, impiegando le librerie di computer vision OpenCV, che rappresentano quanto di meglio esista per il processing di immagini bidimensionali.
Il lavoro si è articolato in 3 fasi:
Fase1: vertical page splitting: conversione in colonna singola. Il nostro approccio prevede di esaminare il numero dei pixel neri nelle righe e nelle colonne, e di identificare le colonne esplorando la derivata del segnale rappresentato dal numero dei pixel. In questa immagine il conteggio dei pixel è rappresentato in blu per le righe e in rosso per le colonne. In ciano si rappresentano le colonne del testo, da tagliare.

Le due mezze pagine vengono poi collimate e giuntate in senso verticale. Il file che ne risulta è meglio processabile con tecnologie OCR.

Fase2: Si procede al line splitting e line boxing: identificazione e conteggio delle righe.
Di seguito l’output del filtro per l’identificazione delle righe, che illustra un possibile problema: L’immagine proviene dalla pagina 0347 (progressione di scansione) del vocabolario. Il filtro adotta una serie di accorgimenti per identificare gli spazi tra le righe di testo, e per costruire il boxfile. In questo esempio si nota un errore di identificazione alla riga 26.
Il problema è stato causato dalla macchina che compare sopra alla parola “Pota” alla riga che scompensa l’algoritmo di identificazione riga. Errori di questo genere richiedono di editare la pagina della scansione originale, rimuovendo l’artefatto, e di rieseguire le fasi di elaborazione, che comunque sono piuttosto veloci.

Si procede alla correzione dei pixel, per rimuovere l’artefatto, con il bitmap editing (utilizziamo il software paint.net):

E dopo la correzione l’algoritmo identifica e conta correttamente le righe.
L’algoritmo da noi prodotto gestisce correttamente ineguali distanze tra le righe (causate da impianti tipografici non digitali) e acquisizioni da scansioni affette da difetti di acquisizione o zoom. Si tiene conto inoltre di una serie di particolari accenti e segni diacritici, come la cediglia, o la croce sotto la lettera, presente in questo testo.

Fase3: Identificazione ed estrazione dei termini. In questa fase un altro algoritmo processa ogni riga per identificare ognuno dei termini oggetto di definizione nel dizionario. Dobbiamo identificare la parola, rappresentata in grassetto e terminante con virgola, che appunto è l’oggetto di ogni definizione del dizionario (termini).
I termini vengono salvati sotto forma di piccole immagini, nei cui nomi file compaiono le coordinate di estrazione (pagina e pixelbox), processabili individualmente tramite funzioni OCR operanti lettera per lettera (per evitare gli ovvi problemi di inadeguato riconoscimento visto che non esiste un dizionario di correzione ortografica e che quello dell’italiano non va bene.)
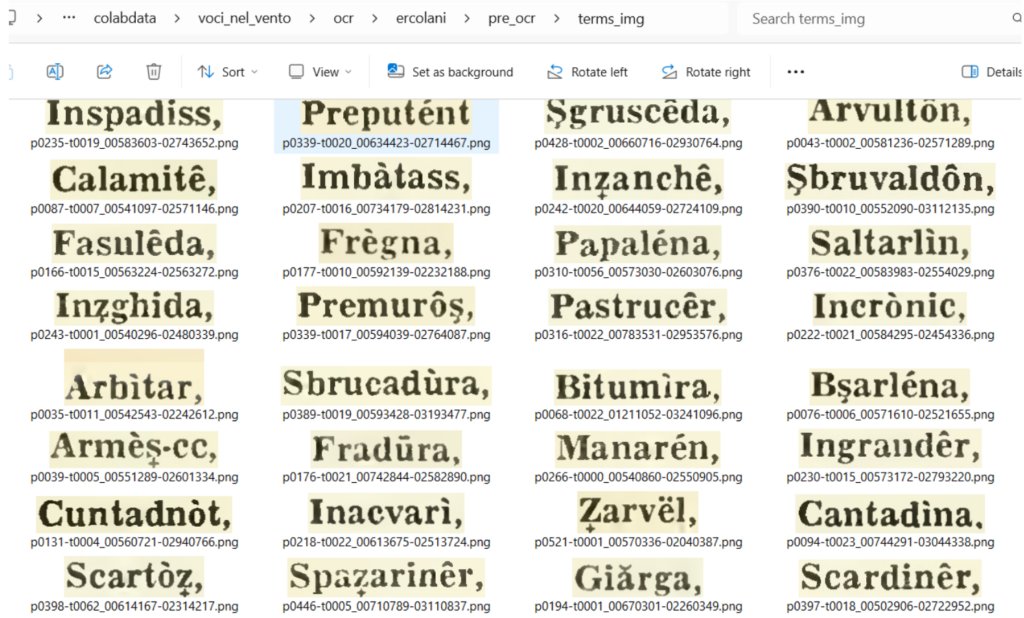
Siamo particolarmente soddisfatti del processo descritto e del codice, che riteniamo valido per effettuare acquisizioni anche da altri testi importanti (pur con le necessarie modifiche). L’esecuzione di funzioni OCR senza adeguata preparazione è infatti prona a numerosi errori che rendono i risultati inservibili.