Nella definizione dei moduli operativi per la analisi delle fonti, abbiamo deciso di adottare metodologie per quanto possibili standard e aperte, che impieghino gli strumenti della moderna linguistica computazionale.
Esito di questo approccio potrà essere una migliore evoluzione, sulla base dell’aggiornamento dei componenti costitutivi, nonchè migliore scalabilità, e possibilità di porting su altri contesti linguistici minoritari di cui l’italia è particolarmente ricca.
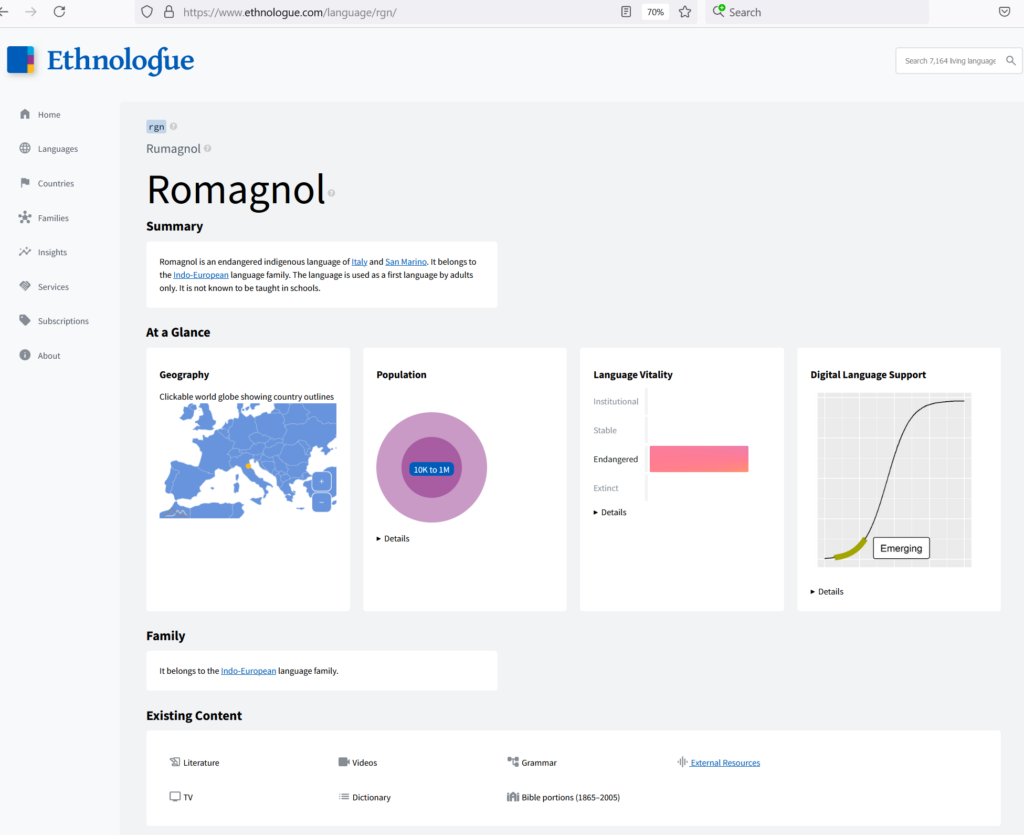
Un percorso per quanto possibile standardizzato e coerente con le ricerche accademiche si basa su solide basi scientifiche, e consente di fruire del lavoro compiuto da altri in attività di classificazione linguistica, sedimentando materiale linguistico standardizzato che aumenta il digital language support rating per la lingua romagnola, (“rgn” nel sistema di classificazione ISO 639-3), al momento classificato come “emerging”.
Il Romagnol [rgn] è una lingua riconducibile alla famiglia delle lingue indoeuropee, secondo la seguente gerarchia
Indo-European
Italic
Latino-Faliscan
Romance
Italo-Western
Western Romance
Gallo-Romance
Gallo-Italic
Emilian–Romagnol
Romagnol
In merito alle classificazioni linguistiche, si vedano anche:
la pagina relativa alla lingua romagnola di Ethnologue, languages of the world,
- la pagina Romagnol di glottolog roma1328
- la pagina di wikipedia
- la pagina lexibank che contiene anche una serie di termini con le relative espressioni fonetiche in IPA, tratte dalla classificazione di Mikhail Saenko (2015)
(per le rappresentazioni dei caratteri IPA, può essere utile installare il font DOULOS SIL o il font CHARIS SIL)
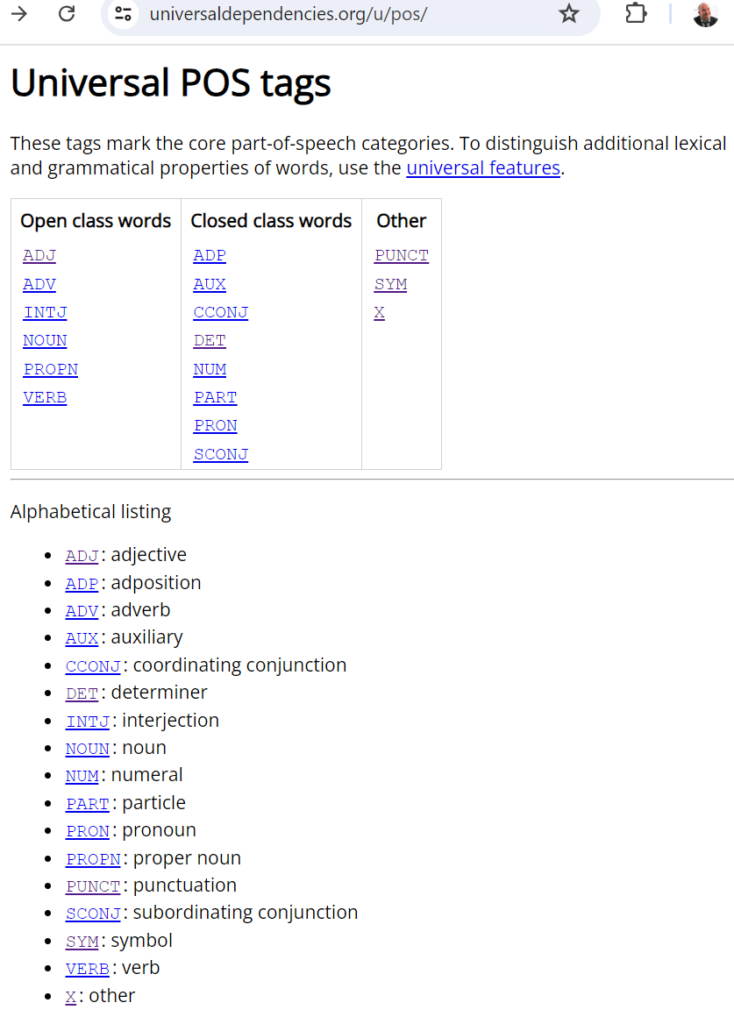
Tra gli approcci di riferimento adottati vi è quello del dipartimento di linguistica dell’università tedesca di Leipzig, che mantiene una corpora collection di testi in oltre 200 lingue, con liste di parole, identificativi POS (parts of speech), e classificazioni con i relativi identificatori universali (UD17 pos tags), come definiti in universaldependencies.org
Abbiamo considerato di utilizzare quanto disponibile su corpusitaliano.it ma questo progetto appare non aggiornato dal 2012.
Al termine del nostro lavoro, vorremmo contribuire i risultati a questi e ad altri repository globali, per aumentare il materiale disponibile, e consentire approfondimenti e ulteriori sviluppi dell’analisi linguistica da parte di altri studiosi.
Il lavoro da svolgere consiste nel classificazione delle parti del discorso nelle frasi in lingua romagnola. Per questo stiamo sviluppando strumenti di labeling, basati su linguaggio python.
Le componenti già etichettate e classificate, vengono apprese, e si procede in via progressiva e incrementale.
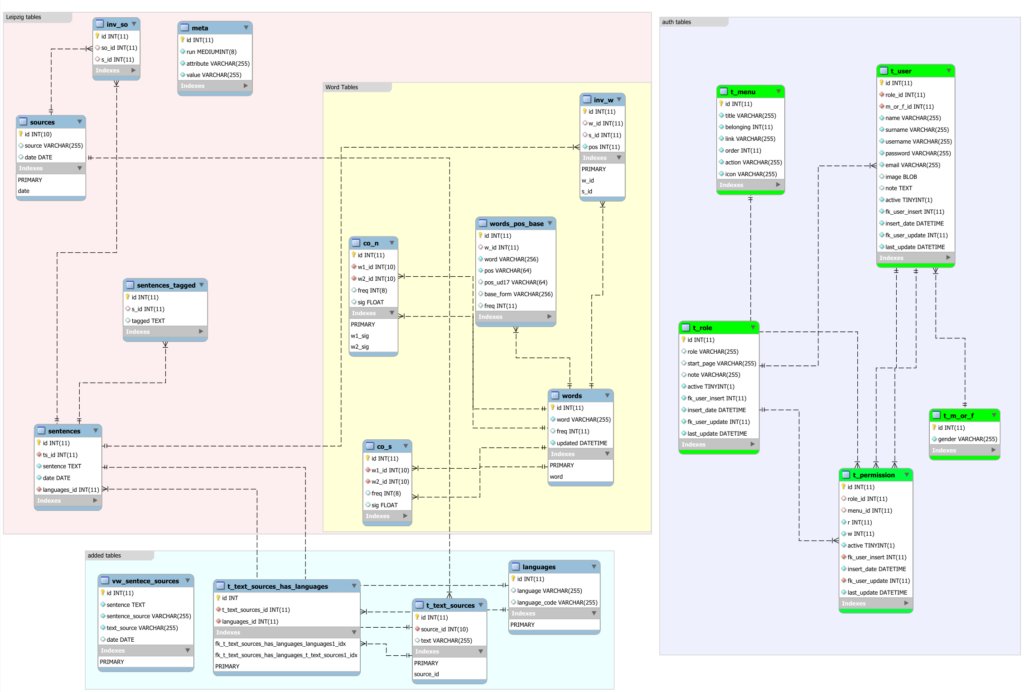
La seguente immagine illustra il modello dati che adottiamo, sulla base dello standard dell’univ. di Leipzig.
( pagina in corso di lavorazione )